
Why is it important to standardize datasets?
Data standardizing is a common practice in data science and machine learning. What does it actually mean and why is it beneficial?
Definition
Standardizing a dataset means to transform the data so that it has a mean of 0 and a standard deviation of 1. This is often done by subtracting the mean from each data point and then dividing by the standard deviation.
Visually, this means turning a dataset like this:

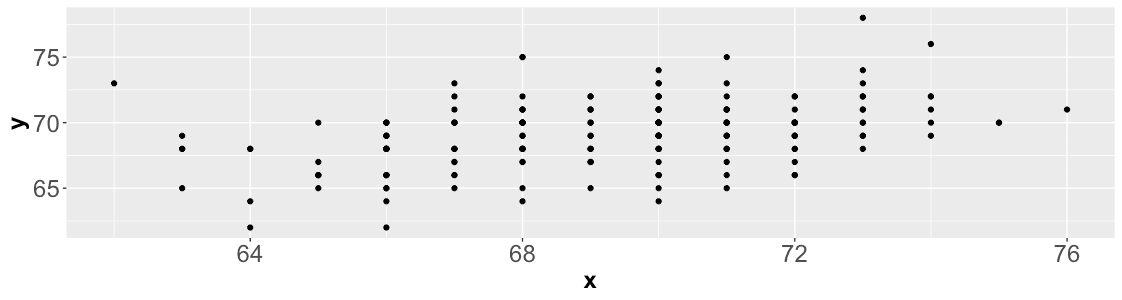
Into this:

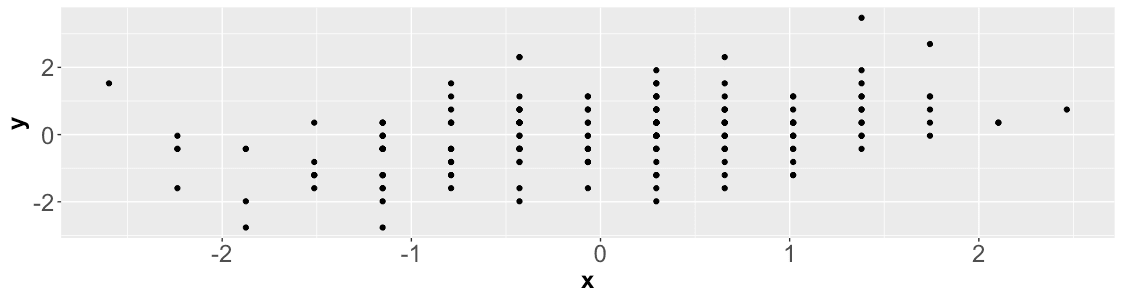
Let’s see some of the benefits of standardizing:
Accuracy
Standardizing allows for more accurate comparisons between data points. If two data points are on different scales, it can be difficult to tell if they are actually different from each other or if the difference is just due to the scale. Standardizing the data eliminates this issue.
Performance of machine learning algorithms
Another reason why standardization is important is that it can help improve the performance of machine learning algorithms. Many machine learning algorithms are based on gradient descent, and they require that all features be on a similar scale in order to work properly. If the features are not standardized, the algorithm may have a hard time converging on a solution.
Avoiding Outliers
Finally, standardization can also help to reduce the amount of noise in the data. If there are a lot of outliers in the data, they can have a significant impact on the results of any analyses that are performed. Standardizing the data can help to filter out some of the noise and make the results more reliable.
We hope this post gave you some insights into the popular concept of standardizing datasets in data science and its many benefits.
Check out this post in:
Medium: https://medium.com/@artofcode_/why-is-it-important-to-standardize-datasets-f94545786d14
Dev.to: https://dev.to/christianpaez/why-is-it-important-to-standardize-datasets-55md
Image credit: https://unsplash.com/@mbaumi