How is a URL structured?
A huge part of modern software is related to web technologies, mostly done by a web server interpreting a URL (Uniform Resource Locator) to locate a resource. In this short writing we will learn how a URL is structured and interpreted.
URL Example
https://example.com:443/path/file.html?key1=value1&key2=value2#SomeLocationInDocument
A URL like this one is divided into multiple components:
Scheme (Required)
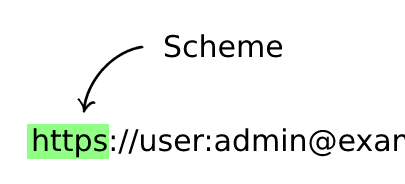
Indicates the protocol that has to be used to request the resource, can be either https (With SSL/Secure) or http (Without SSL/Unsecure).
User (Optional)
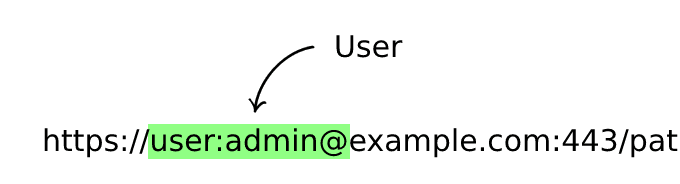
Used for HTTP Basic Authentication, currently deprecated since it is prone to security flaws, is written in the form user:password followed by an @ sign.
Host (Required)
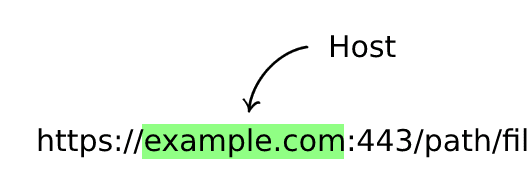
This is the resource location, could be an IP address (e.g., 192.0.2.146) or a host name (e.g., example.com). a host name can include a subdomain followed by a dot . before the domain name (i.e., subdomain.example.com) and has to include a top-level domain (e.g., .com).
Port (Optional)
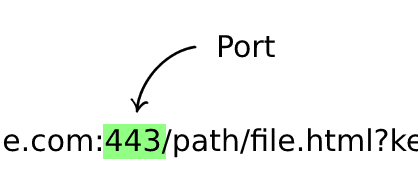
This number indicates the web server port number we want to connect to, denoted after the host and preceded by colon : defaults to 443 for https and 80 to http.
Path/Directory (Optional)
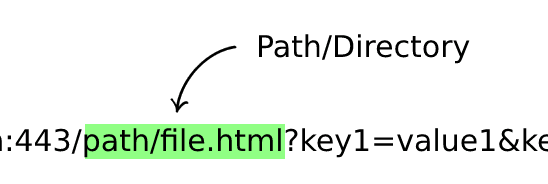
Points to the resource we want to access, can be a file or a folder; all web applications have a default path, usually index.html.
Query String (Optional)
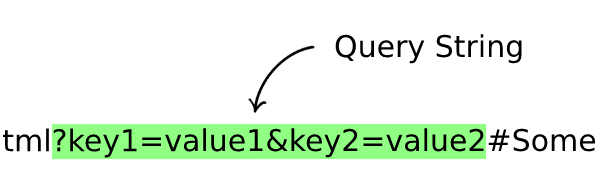
These are extra parameters sent to the web server, starts with a question mark ?
followed by one or many key value pairs in the form key=value.
Fragment/Anchor (Optional)
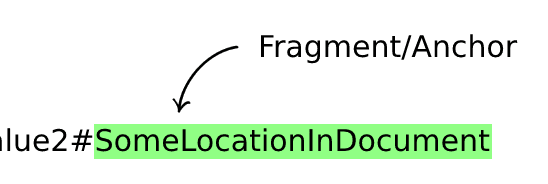
This is used by the locate sections within the document displayed by the browser; this value is only processed on the client.
As you can see, there is a lot going on in a URL string, we hope this short writing can provide useful info as to what these values mean.
Check this post on:
Dev.to: https://dev.to/christianpaez/how-is-a-url-structured-4jkl
Medium: https://medium.com/@artofcode_/how-is-a-url-structured-3186015a8287